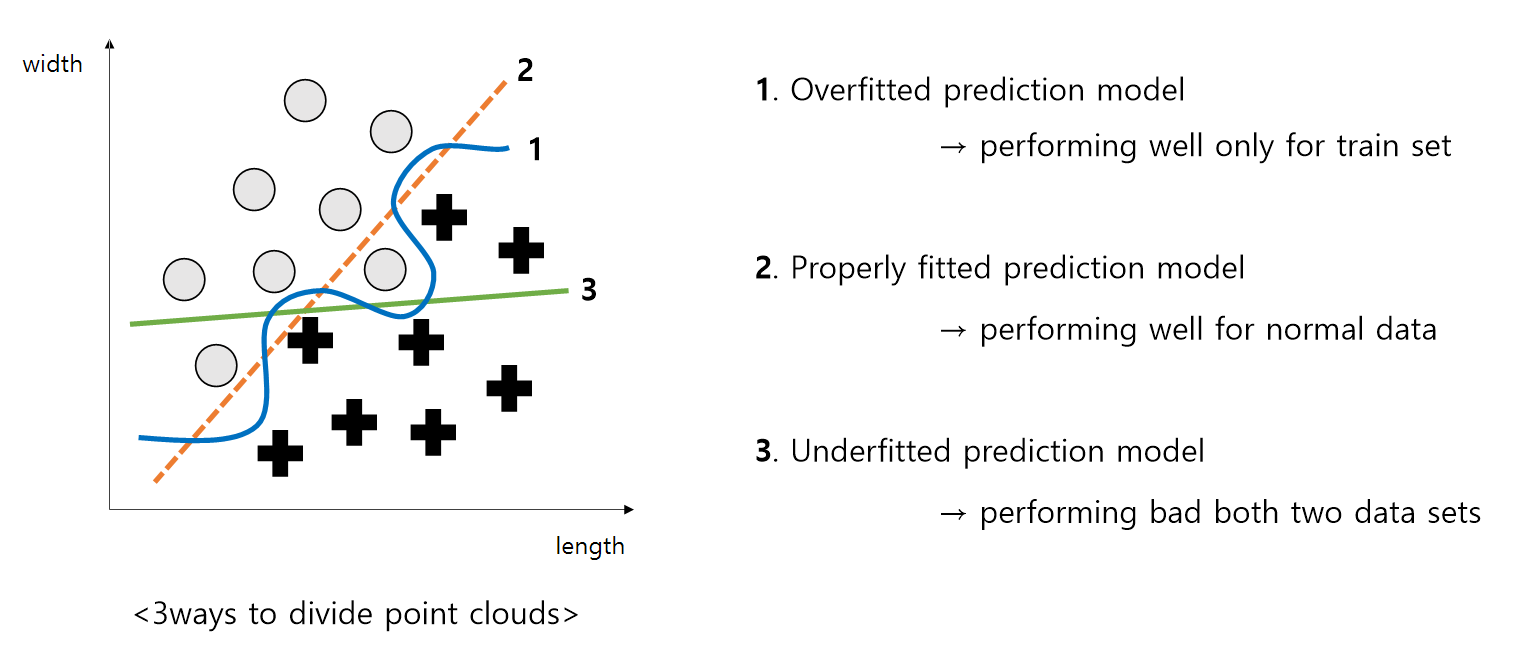
안녕하세요, 오늘은 [논문리뷰]를 진행하며 알아본 불균형 데이터셋에서의 샘플링 전략 적용을 위한 코드 구현법에 대해서 알아보겠습니다. [논문 리뷰] Decoupling representation and classifier for long-tailed recognition(롱테일 인식을 위한 특징 추출기1. Introduction ImageNet과 같은 거대한 데이터셋들을 주로 활용하면서, 딥 CNN신경망과 함께 이미지 분류 모델은 엄청난 속도로 발전해왔습니다. 이러한 데이터셋들은 모델 훈련시 준수한 성능을 낼deep-learning00.tistory.com 해당 논문에서는 데이터셋 클래스간 불균형을 극복하기 위해 리샘플링 전략을 사용했습니다. 가공 전의 데이터셋은 클래스마다 샘플의 숫자가 다르기..