최근 엔비디아(NVIDIA)의 시가총액이 무려 846조 원이나 증발하는 사건이 있었는데요, 그 이유는 다름 아닌 DeepSeek라는 모델의 등장 때문입니다.
중국의 연구팀이 개발한 이 모델은 기존의 AI 모델들이 필요로 했던 고가의 H100 GPU 대신, 저사양 H800 GPU로도 GPT-4에 필적하는 성능을 구현해내는데 성공하였고, 개발팀은 DeepSeek 모델을 오픈소스로 공개하였습니다.
이 발표로 고성능 AI 칩에 대한 수요 감소가 예상되며 엔비디아의 주가 하락까지 이어지게 되었습니다.
이번 포스팅에서는 DeepSeek-R1 논문을 리뷰하며 논문의 메인 컨트리뷰션과 기술적 특징, 그리고 논문에 제시된 성능지표들을 살펴보도록 하겠습니다.
https://arxiv.org/abs/2501.12948
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasonin
arxiv.org
메인 컨트리뷰션
1. 사후 학습 단계에서 강화 학습만을 사용
2. 증류(distilation)를 통해 작은 모델로도 높은 성능 달성
1. 사후 학습 단계에서 강화 학습만을 사용

보통 LLM을 학습시킬 때, 사전 학습(Pre-training) 단계를 거쳐 언어 이해 및 문맥 생성 능력을 갖추게 하고, 후에 사후 학습(Post-training)으로 응답 품질 개선 혹은 특정 작업에 대한 최적화 능력을 갖추게 합니다.
1.1 논문에서는 베이스 모델로 Pre-trained 모델인 DeepSeek-V3-Base 를 사용하였고, GRPO(Group Relative Policy Optimization) 알고리즘을 사용하여 모델이 Chain-of-Thought를 스스로 탐색하여 자기 검증 및 반성 능력을 습득할 수 있게 하였습니다.

1.2 GPRO 알고리즘으로 사후 학습을 진행하여 추론 능력을 강화시킨 모델을 DeepSeek-R1-Zero라고 합니다. 보통의 LLM에서는 사후 학습 단계에서 감독 학습을 주요 기법으로 사용합니다만, 딥시크는 이 단계에서 강화학습만을 사용하였고, 논문에 이 부분을 메인 컨트리뷰션으로 제안하고 있습니다. 하지만 강화 학습을 마친 DeepSeek-R1-Zero 모델에서 가독성 부족과 언어 혼합문제가 발생합니다.
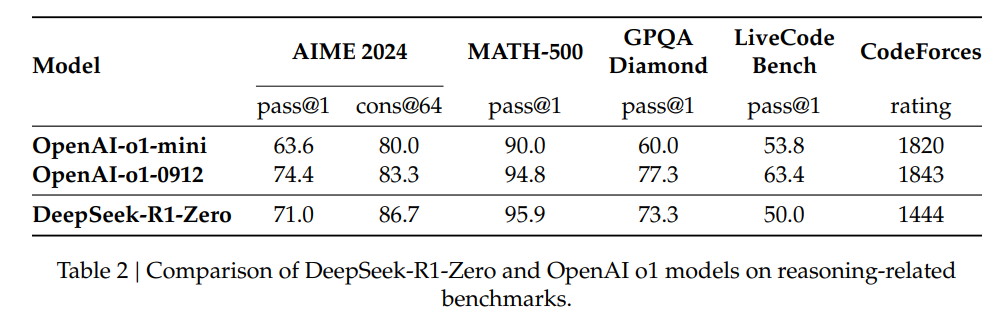
(AIME 2024, MATH-500, GPQA Diamond, LiveCode Bench, CodeForces는 모델의 코딩 능력, 수학 문제풀이 능력등을 평가하는 지표입니다)
1.3 이 문제를 해결하기 위해 추가적인 학습을 시켜주게 되는데요. Cold Start데이터로 감독 학습을 수행시켜 가독성 문제를 해결했으며, 추론 지향 강화 학습으로 다양한 작업(수학, 코딩, 지식 테스트 등)에 대한 모델 성능을 최적화 한 모델을 얻었습니다. 이렇게 얻은 최종 모델이 바로 DeepSeek-R1이며, GPT-4o0513보다 우수한 성능을, OpenAI의 o1-1217와 비슷한 성능을 달성했습니다.


2. 증류(distilation)를 통해 작은 모델로도 높은 성능 달성
또한 지식 증류(knowledge distilation)을 통해 DeepSeek-R1이 학습한 추론 패턴을 소규모 모델로 증류합니다. 지식 증류 기법으로 DeepSeek-R1의 추론 패턴을 소형 모델 (Qwen-7B, Llama-8B 등)에 적용하여 연산 및 메모리 비용을 줄이면서도 높은 성능을 유지하였습니다.
소규모 모델은 대규모 모델이 (Chain of Think)방식과 추론 패턴을 효과적으로 학습합니다. 소형 모델은 메모리와 연산 비용이 적어 로컬 환경에서도 실행이 수월해진다는 장점이 있습니다.

B는 billion단위, 파라미터 수를 의미합니다. 위의 표에서 DeepSeek-R1의 토탈 파라미터 수가 671B였던 것과 비교했을 때 파라미터 수가 굉장히 적다는 것을 알 수 있으며 성능 또한 기존의 소형 모델들과 비교했을 때 준수하다는 것을 확인할 수 있습니다.
오픈소스로 개방한 딥시크
https://api-docs.deepseek.com/news/news250120
DeepSeek-R1 Release | DeepSeek API Docs
* ⚡ Performance on par with OpenAI-o1
api-docs.deepseek.com

싼 가격에 딥시크의 API를 제공합니다. 개발자분들에게 유용할 것으로 보여집니다.
https://github.com/deepseek-ai
DeepSeek
DeepSeek has 16 repositories available. Follow their code on GitHub.
github.com
github에서 코드 역시 확인할 수 있습니다. 연구자분들도 도움을 많이 받을 수 있을것으로 보여지네요~ (학습용 데이터셋은 제공하지 않습니다.)