안녕하세요! 오늘은 DiTMoS 논문을 리뷰해보도록 하겠습니다. DiTMoS는 기존의 "상향식(top-down)" 모델 압축 전략에서 벗어나, 처음부터 "하향식(bottom-up)"으로 설계된 다수의 약한 모델을 조합하여 높은 정확도를 달성하는 새로운 프레임워크인데요, 이 DiTMoS 프레임워크를 통해 모델의 사이즈를 크게 줄여내며 SRAM이 제한된 마이크로컨트롤러에서의 인공지능 서빙(추론)이 가능하게 했습니다.
PerCom 2024 best paper받은 논문입니다 함께 보시죠~
https://arxiv.org/abs/2403.09035
DiTMoS: Delving into Diverse Tiny-Model Selection on Microcontrollers
Enabling efficient and accurate deep neural network (DNN) inference on microcontrollers is non-trivial due to the constrained on-chip resources. Current methodologies primarily focus on compressing larger models yet at the expense of model accuracy. In thi
arxiv.org


Fig. 1을 보시면 Top-down 메소드와 Bottom-up 메소드가 제시되어 있습니다. 프루닝과 양자화, 지식 증류(KD)와 같은 방법으로 모델을 압축하는 방식이 Top-down방식, 작은 모델 여러개를 둔 후에 model selector를 두어 입력에 대해서 어떤 모델에 대한 출력을 최종 출력으로 선택할지 결정되는 방식이 Bottom-up 방식입니다.(인간활동, 키워드 감지, 감정인식과 같은 간단한 1차원 시계열 데이터셋을 사용한 분류 작업)
기존에 Top-down 방식만 공부하던 저는 bottom-up 방식에서 작은 모델을 여러개 둔다고 해서 정확도가 올라갈까하는 의문이 있었는데요. 논문에서는 이에 대한 observation을 제시합니다.

CKA 행렬은 모델 간 feature extraction파트에서의 유사도를 측정하는 대표적인 방법입니다. 강한 모델 5개에서는 높은 유사도를 보이는데, 이건 모델들이 서로 유사한 특징들을 학습하였다라는 것을 의미하고, 일반적으로 모든 입력에 대해서 잘 추론해낼 수 있게 훈련되었다는 것을 의미합니다. 반면에 약한 모델 5개는 모델 간 유사도가 적게 나타나는데, 이는 모델간의 다양성이 더 크다는 것을 의미합니다.

약한 모델의 크기가 강한모델보다 약 17배 정도 적다는 것을 확인할 수 있습니다. 그리고 모델 각각의 정확도는 낮게 측정되지만, Union accuracy로는 준수한 정확도를 보임을 알 수 있습니다. (Union accuracy란 적어도 하나의 분류기에 의해 올바르게 분류된 샘플의 비율을 뜻합니다.)
즉, 약한 모델들을 분업화시켜 학습을 시킨 다음, 셀렉터가 각 입력마다 서빙할 모델을 선택하게 만들어 주어서 union accuracy를 끌어올리는 방법이 bottom-up 방식입니다.

훈련과정은 서버 컴퓨터에서 이루어집니다. 데이터셋을 K-Means 알고리즘으로 분류기와 같은 개수인 m개로 나눈 후에 classifier들은 각각 나누어진 데이터들을 학습합니다. 각 분류기들이 분업하여 학습한다 라고 이해할 수 있습니다.
어떤 분류기가 선택될지 결정하는 selector 역시 학습되어야 하는데, 각 샘플에 대해 올바르게 분류한 분류기에는 1, 그렇지 못한 분류기에는 0으로 레이블을 부여하여 BCE 손실을 최소화하는 방법으로 학습됩니다.

feature aggregation 기법도 사용됩니다. 각 분류기들이 제한된 데이터 서브셋만 학습한 한계를, 셀렉터에서 얻은 전역 특징을 활용할 수 있게 만들어 정확도를 높입니다. 약간의 추론속도를 지연시킨다는 단점이 있습니다.
Feature Aggregation
1. 입력 데이터가 셀렉터로 들어간다(이 과정에서 얻은 1번째와 2번째 특징맵을 저장해둠)
2. 어떤 분류기가 사용될지 결정된다
3. 결정된 분류기로 입력 데이터가 들어간다
4. 저장해둔 특징맵들을 concat하여 최종 output을 내는데 반영한다
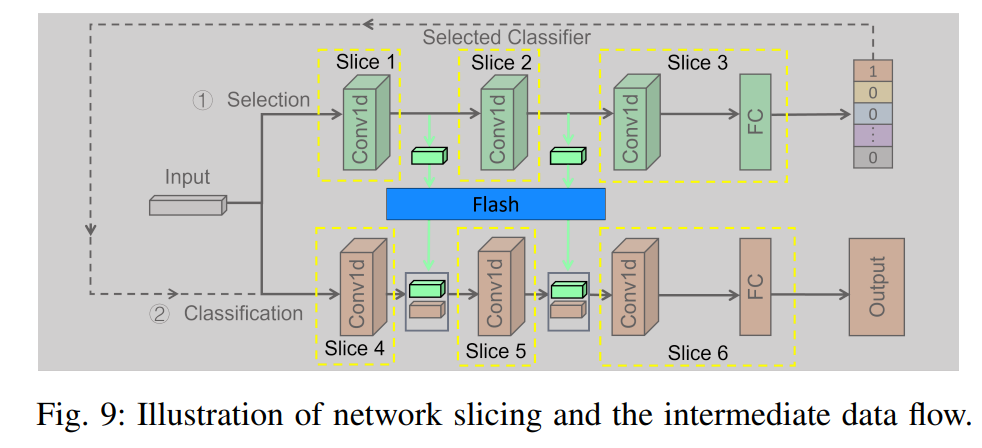
셀렉터에서 얻은 특징맵을 저장해놓는 과정에서 추가 메모리 소요가 발생하는데, 논문에서는 플래시를 두어 이 점을 보완해줍니다.
실험결과 그래프, 테이블과 함께 논문리뷰 마치겠습니다. 감사합니다.


