안녕하세요 Pruning Filters for Efficient ConvNets 논문 리뷰 시작하겠습니다.
1. Abstract & Introduction
∙ 다양한 application에서 활용되는 CNN은 큰 연산량과 저장공간이 동반된다
∙ 최소한의 성능 감소로 convolution layer의 filter들을 pruning, 모델의 연산량을 줄일 수 있다
∙ 모델을 압축하려는 시도는 많았으나 fully connected layer에서의 pruning은 유의미한 연산 시간의 차이를 만들지 못했다
∙ VGG-16을 예로 들면 단 1%의 부동소수점 연산만이 fully connected layer에서 이루어진다
∙ Filter pruning & retrain 전략으로 정확도를 크게 희생하지 않고도 연산량을 크게 줄여 모델의 속도향상을 이끌어 낼 수 있다
2. Pruning filters and feature maps
먼저 필터 하나를 제거했을 때 컨볼루션 네트워크의 변화를 살펴보겠습니다.

이 논문에서는 kernel matrix를 통해 필터들을 표현하는데, 각 열이 하나의 필터를 의미합니다.(첫번째 필터는 kernel matrix의 1열에 해당)
위 그림을 요약하면 4번째 필터가 먼저 제거 된 후에, 4번째 필터가 제거되었으므로 원래라면 출력되었야하는 4번째 feature map이 출력되지 않게 됩니다.
그리고 이는 다음 컨볼루션 레이어에서 모든 필터들의 4번째 커널들 역시 제거되게 합니다.
위 사진에서 이러한 방식으로 감소시킨 연산량도 확인할 수 있습니다.
2.1 각 레이어에서 어떤 기준으로 필터를 제거할 것인가
컨볼루션 레이어의 필터들 중 가장 영향력이 적은 필터를 지우는 것이 성능 감소를 최소화 할 수 있습니다.
논문에서는 다음과 같이 필터의 중요도를 측정하는 방법을 제안합니다.

정렬한 필터들을 그래프로 그려보고, 시각화해보면 다음과 같습니다.
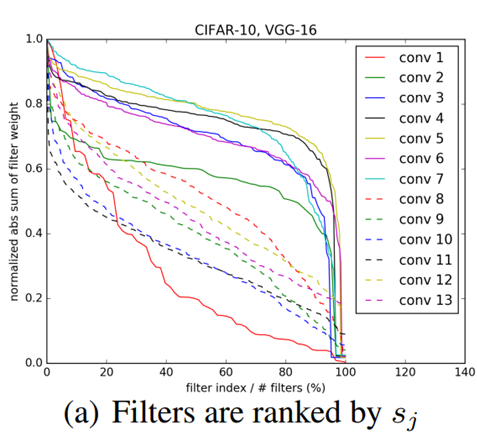

또한 l1-norm을 기준으로 작은 순서대로 필터를 제거했을 때, 랜덤하게 제거했을 때, 큰 순서대로 필터를 제거했을 때의 정확도를 비교한 결과도 제시합니다.

2.2 연속적인 레이어에서의 커널 프루닝
고려해야 할 사항이 한가지 더 있습니다. 이전 레이어의 필터 제거로 없어진 커널을 다음 레이어의 l1-norm 에 포함시켜야 하냐는 문제입니다.

1. Independent Pruning
: 필터의 norm 계산 시 전 layer에서 pruning으로 제거된 커널을 고려하지 않음
2. Greedy Pruning
: 필터의 norm 계산 시 전 layer에서의 pruning으로 제거된 커널을 고려함
2.2 재학습 방법 두 가지
연속 프루닝 방법을 정했다면 재학습 방법을 정해주면 됩니다. 재학습 방법도 두가지를 제안합니다
1. Prune once and retrain
: Multiple layer의 pruning을 모두 진행 후 원래의 성능이 복원될때까지 모델 재훈련 진행
> 적은 시간 재훈련으로도 정확도 감소를 보완해줄 수 있음
> 그러나 중요한 필터가 제거되거나 네트워크의 많은 부분이 제거되는 경우 정확도 회복이 힘듦
2. Prune and retrain iteratively
: layer 별로 pruning 진행 후 모델 재훈련을 각 layer마다 반복 진행, 다음 레이어의 pruning이 진행되기 전에 재훈련됨
> 중요한 필터가 제거되는 문제점을 해결해 줄 수 있음
> 그러나 학습에 많은 에포크를 요함
3. Experiment & Conclusion
논문은 VGG16 on CIFAR-10, ResNet-56 on CIFAR-10, ResNet-34 on ImageNet 이렇게 3가지 실험 결과를 정리합니다.

각 조건에서 연산량 감소와 파라미터 감소량, 에러율을 다음과 같이 보고합니다. 오히려 pruning한 모델의 정확도가 더 좋다는 것을 확인할 수 있었습니다.
논문에서는 가중치가 작은 필터를 프루닝하여 계산 비용을 줄이는 방법을 제안하며, 정확도 손실을 거의 발생시키지 않으면서도 VGGNet과 ResNet에서 FLOP을 약 30% 감소시켰습니다.