1. Introduction
ImageNet과 같은 거대한 데이터셋들을 주로 활용하면서, 딥 CNN신경망과 함께 이미지 분류 모델은 엄청난 속도로 발전해왔습니다.
이러한 데이터셋들은 모델 훈련시 준수한 성능을 낼 수 있게 하기 위해 각 클래스마다 샘플(이미지) 개수들이 균형을 이루고 있는데요,
하지만 항상 이렇게 균형잡힌 데이터셋을 활용하여 모델을 훈련시킬 수 있는 것은 아닙니다. 인터넷상에 충분한 양의 이미지 자료가 퍼져 있지 않은 물체를 학습시킬 때를 그 예로 들 수 있겠죠.

long-tail 데이터셋이란 그림과 같이 샘플 수가 많은 클래스와 샘플 수가 적은 클래스간의 샘플 수 불균형이 큰 데이터셋을 뜻합니다.
논문에서는 클래스넘버가 클수록 샘플 수가 많은 클래스입니다. 샘플 수를 기준으로 내림차순 정렬하여 클래스 넘버를 주었습니다.
하지만 이러한 롱테일 데이터 분포를 따르는 데이터셋으로 훈련시킨 모델에서는 정확도가 크게 떨어지는 현상을 확인할 수 있는데요.
롱테일 데이터셋으로 훈련시킨 이미지 분류 모델은 헤드 클래스에 대한 예측 정확도는 좋으나 테일 클래스들에 대한 예측 성능은 매우 떨어진다는 점입니다.
이 논문에서는 이러한 롱테일 상황에서의 정확도 감소를 해결하기 위해 Decoupling(디커플링)이라는 아이디어를 제시합니다.
CNN분류기는 크게 특징 추출기(representation)와 분류기(classifier)로 나눌 수 있습니다.
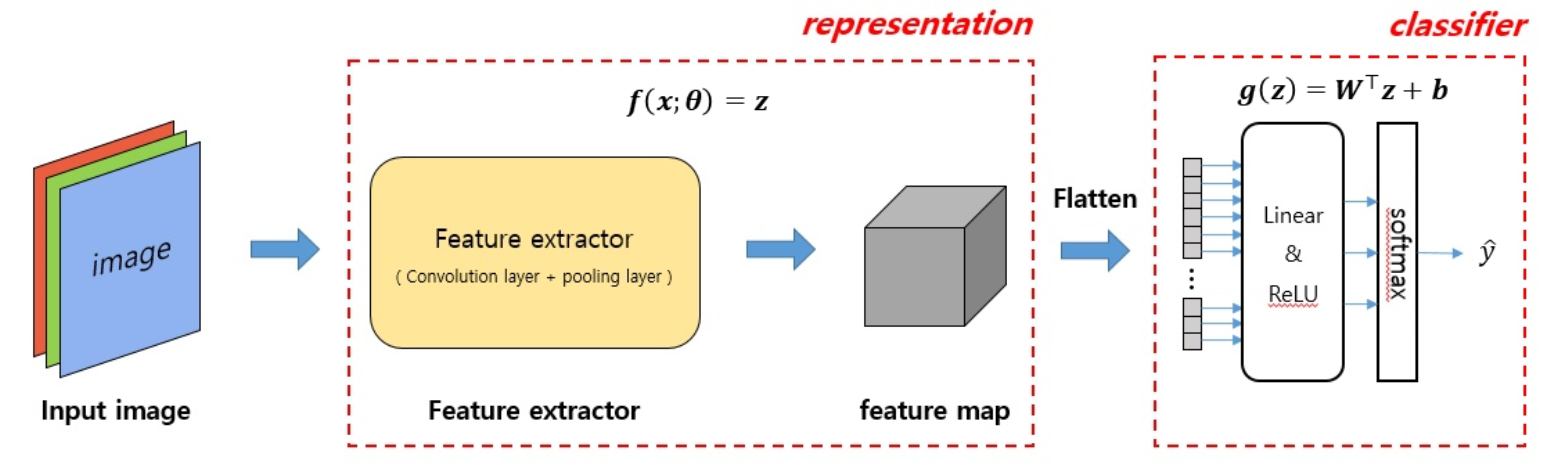
CNN 이미지 분류기는 라벨링된 이미지가 특징 추출기와 분류기를 거쳐 한번에 학습됩니다.
그러나 이러한 방법의 학습이 끝나고 나면 결과 분석시에 이 모델의 성능에 특징 추출기와 분류기 중 두 파트가 모델의 성능에 각각 어떠한 영향을 끼쳤는지 알 수가 없습니다.
성능이 잘나왔다고 가정하면, 특징 추출기가 좋은 필터를 학습하여 모델의 전체 정확도가 상승했는지, 분류기가 훌륭한 decision boundary를 만들어 모델의 전체 정확도가 상승한 것이지 판단이 힘들다는 것입니다.
이 논문은 이 점에 주목하여 두 파트에서 각각 어떠한 샘플링 전략을 선택하여 훈련하였을 때 롱테일 상황에서 최고의 성능을 내는지를 비교합니다.
2. Related work
data distribution re-balancing, class-balanced losses, transfer learning from head to tail classes 연구 등이 제시되어 있습니다.
3. Learning representations for long-tailed recognition
우선 논문에서의 표기법을 정리하고 가겠습니다.

W와 b는 각각 분류기의 웨이트와 바이어스를 뜻합니다.
다음으로는 4가지 샘플링 전략입니다. 이 샘플링 전략을 통해 배치를 구성하는 샘플들이 뽑힐 때의 확률을 조정합니다.

- Instance-balanced sampling : 각 클래스의 샘플들이 배치에 뽑힐 확률이 샘플 분포와 같습니다.
- Class-balanced sampling : 각 클래스의 샘플들이 배치에 뽑힐 확률이 모두 같습니다.
- Square-root sampling : 데이터 분포에 1/2 제곱을 따릅니다.
- Progressively-balanced sampling : 에포크가 진행됨에 따라 확률이 균등해집니다.
4. Classification for long-tailed recognition
1차 훈련으로 특징 추출기를 학습시킨 후에 분류기 파라미터 재조정 또는 재훈련을 통해서 long-tail 훈련된 분류기의 성능을 끌어올립니다.
분류기 재조정에는 크게 4가지 방법이 있습니다.
(1) Classifier Re-training(cRT)
- 특징 추출기는 고정한 후, 랜덤하게 분류기의 웨이트 W와 바이어스 b를 초기화하고 class-balanced 샘플링을 통해 재학습시킵니다.
(2) Nearest Class Mean classifier (NCM)
- 코사인 유사도나 유클리디안 거리를 이용한 최근접 이웃 알고리즘으로 분류기를 재훈련합니다.

(3) τ-normalized classifier (τ-normalized)
- 헤드 클래스의 웨이트 놈(norm)이 크다는 사실을 실험적으로 알아냈습니다. (아래의 파란색 그래프)

- 헤드 클래스의 웨이트 놈이 클수록 해당 클래스가 차지하는 특징 공간(feature space)의 크기가 커지고 테일 클래스들은 충분한 특징 공간을 확보하지 못하게 됩니다. 이는 테일 클래스 샘플에 대한 예측 정확도 감소로 이어집니다.

- 헤드 클래스일수록 웨이트 놈이 크고 테일 클래스일수록 작다는 점을 이용하여 하이퍼 파라미터 τ(타우)를 통한 정규화 정도를 설정합니다. ( τ=1일 때 L2 정규화, τ=0 일 때 no scaling)
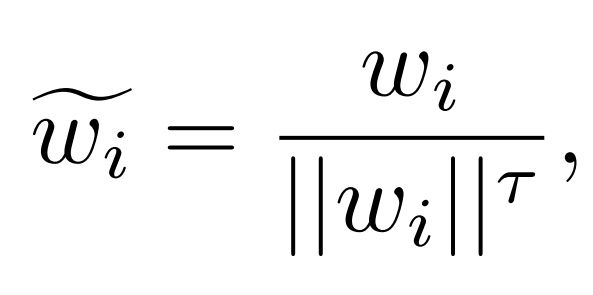
(4) Learnable weight scaling (LWS)
- τ-normalization 을 재해석합니다. τ-normalization의 분모를 학습 파라미터로 두고 나머지 파트는 고정한 후 cRT와 같이 class-balanced 샘플링을 이용하여 f_i값을 얻고 그에 따른 최적화된 τ를 얻습니다.

5. Experiments

그래프의 색은 1차 학습(특징 추출기 학습)에 이용된 샘플링 전략을 의미하고 x축은 사용된 2차 분류기 재조정 기법을 의미합니다.
Instance-balanced sampling을 통한 1차 학습과 cRT, τ-normalization 기법으로 2차 학습시킨 모델이 가장 높은 정확도를 보였습니다.
이를 통해 representation(특징 추출기) 학습에 있어서 클래스 간 샘플 수 불균형은 문제가 되지 않음을 알 수 있습니다.

Table 2 에서 long-tail 상황해결을 위해 진행된 다른 연구기법들(FSLwF, Focal Loss, Range Loss 등등)과의 성능비교표를 정리해두었습니다. 해당 논문에서 제시한 기법들(특히 cRT, τ-normalized, LWS)이 더 좋은 정확도를 보임을 확인할 수 있습니다.
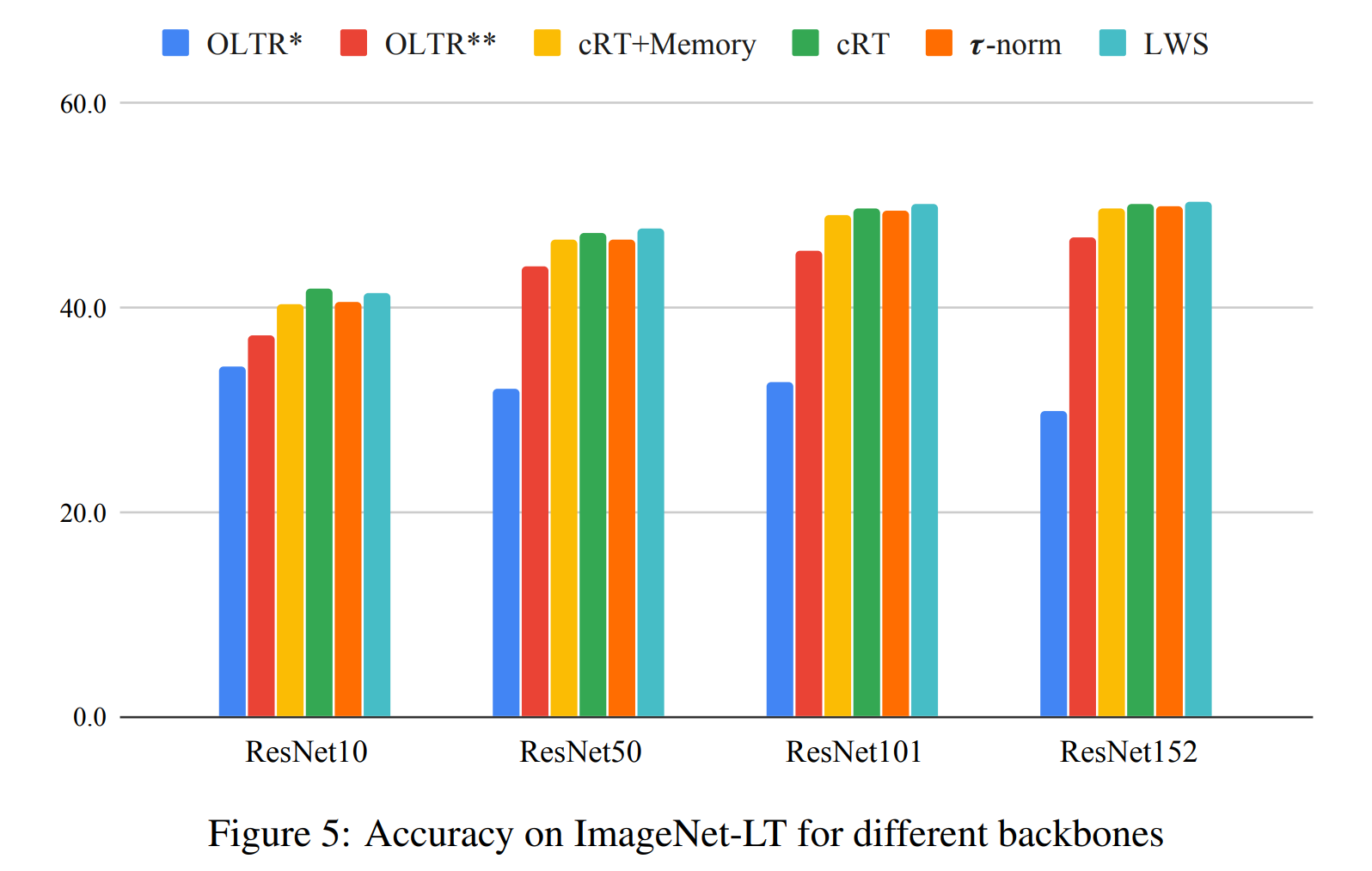
Figure 5는 백본(representation)의 종류에 따른 성능정리표를 보입니다. 크기가 큰 백본을 사용했을 때 우수한 성능을 보입니다.
6. Conclusions
지금까지의 내용과 결과를 요약하면
1. Decoupling으로 이미지 분류기를 representation부와 classifier부로 나누어 생각할 수 있다.
2. 클래스 간 샘플 불균형은 representation부 예측 성능에 영향을 미치지 않는다.
3. cRT와 τ-normalized(+LWS) 기법으로 롱테일 상황에서의 classifier 성능을 끌어올릴 수 있다.
4. 큰 백본을 사용했을 때의 모델이 더 우수한 성능을 낸다.
정도가 될 것 같습니다.
감사합니다~