안녕하세요! 오늘 포스팅에서는 Self-Attention이란 무엇인지, 그리고 그것이 어떻게 작동하는지 알아보겠습니다. Self-Attention을 핵심 연산으로 사용하는 트랜스포머는 LLM과 비전 모델 등 다양한 인공지능 모델에서 활용되며, 뛰어난 성능을 자랑하는 구조입니다. 어텐션 스코어 계산부터 Softmax 적용, 최종 출력 생성까지의 과정을 쉽게 설명해드리겠습니다.

기존의 attention은 입력과 출력 사이의 관계를 파악하기 위해 쓰였으나, Self attention은 입력문장에서 단어와 단어들간의 관계를 파악하기 위한 작업입니다.

self attention은 위 그림의 과정을 거쳐서 출력을 내보내게 되는데요,
"I like a cat" 이라는 예시 문장을 입력으로 어텐션 연산이 진행되는 과정을 보여드리겠습니다.

먼저 입력 문장은 단어 단위로 쪼개지게 됩니다. 그리고 각 단어들은 임베딩 레이어를 거치며 지정된 차원의 벡터로 임베딩됩니다. 위의 그림은 I, like, a, cat 각각의 단어가 [1x64]의 크기의 벡터화 되었음을 의미합니다.(후에 positional embedding단계를 추가적으로 거쳐 문장의 위치 정보 또한 학습할 수 있게 됩니다. 이 과정은 추후에 다뤄보도록 하겠습니다.)

그렇게 벡터화된 Input은 learnable matrix인 W_q, W_k, W_v와 곱해지게 되고 이 값들이 Query, Key, Value가 되어 self-attention연산의 입력이 됩니다.

그렇게 얻은 Query행렬과 transeposed Key 행렬이 곱해져서 4x4의 어텐션 스코어 행렬 QK^T가 됩니다. 이 행렬곱 연산으로 입력문장에서 단어 간의 관계를 파악하게 됩니다. QK^T 행렬의 1,1 은 word1과 word1의 관계를 의미하고, 1,2는 word1과 word2의 관계를 의미하게 되겠죠? 그리고 이 행렬을 sqrt(embedding dimension)으로 나누는 scaling단계를 거칩니다.

이렇게 만들어진 어텐션 스코어는 masking matrix와의 element-wise 곱을 거칩니다. masking layer를 거칠지 말지는 선택이나, masking layer 도입을 통해 파라미터를 줄이기도 합니다.
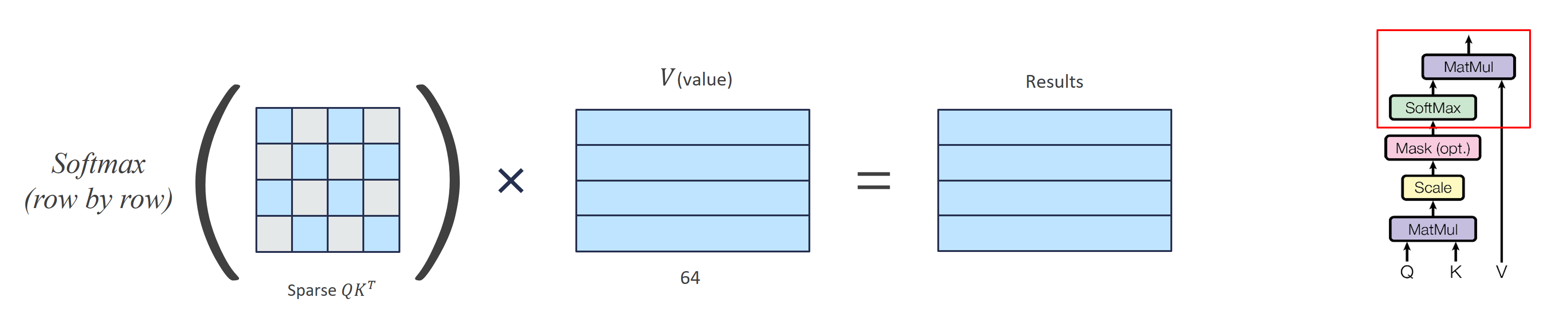
masking layer를 거친 후 sparsed QK^T는 각 행마다 softmax가 적용되어 정규화됩니다. 이 행렬의 1행에, I 와 나머지 단어들 간의 관계가 들어있다고 이해하실 수 있으실 겁니다. 그렇게 정규화된 어텐션 스코어가 value와의 행렬곱을 통해 최종 output이 됩니다. 이 최종 output은 input 문장의 관계성까지 포함하고 있는 문장이라고 볼 수 있겠네요.
'딥러닝 CV&LLM' 카테고리의 다른 글
| [딥러닝 컴퓨터비전] 스테레오 비전을 이용한 3차원 위치추정 알고리즘 (3) | 2024.07.19 |
|---|---|
| [딥러닝 컴퓨터비전] Yolo v8에 IRFS 기법 적용하기 (3) | 2024.06.26 |
| [딥러닝 컴퓨터비전]불균형 데이터셋에 대한 샘플링 전략 적용법 (Pytorch) (2) | 2024.05.06 |
| [딥러닝 컴퓨터비전] Faster R-CNN(two-stage object detection) (2) | 2024.03.27 |
| [딥러닝 컴퓨터비전] YOLO(one-stage object detection) (3) | 2024.03.27 |